
Die Universität Erfurt lud uns ein, im kommenden Sommersemester eine online Coffee-Talk Serie zum FactGrid als kollaborativer Forschungsplattform zu veranstalten. Neun Themenschwerpunkte haben wir ausgesucht. Die Veranstaltungen sollen kurz und für die Mittagspause zum Hineinschnuppern gemacht sein. Lassen Sie sich inspirieren. Wir bieten eine 15minütige Erkundung mit jeweils offener Fragerunde.
Das Link zur Veranstaltung erhalten Sie für eine Mail an olaf.simons@uni-erfurt.de
14.4.2022: Sich beim Forschen über die Schulter sehen lassen? — Isabella Schwaderers Erkundungen zu den Mitgliedern der Schopenhauergesellschaft

Kann man es riskieren, auf einer Plattform, auf der alle Daten unmittelbar offen zugänglich sind, die eigene gerade erst angefangene Forschung laufen zu lassen? Isabella Schwaderer tat diesen Schritt mit ihren Recherchen zu den Mitgliedern der Deutschen Schopenhauergesellschaft und wird hier Einblicke in die Nutzerperspektive geben. Worauf lässt man sich ein? Was ist praktisch? Was ist unpraktisch? Was riskiert man? Was gewinnt man?
21.4.2022: Was immer eine Aussage finden kann, kann ein Datenbank-Item werden — wie Wikibase funktioniert
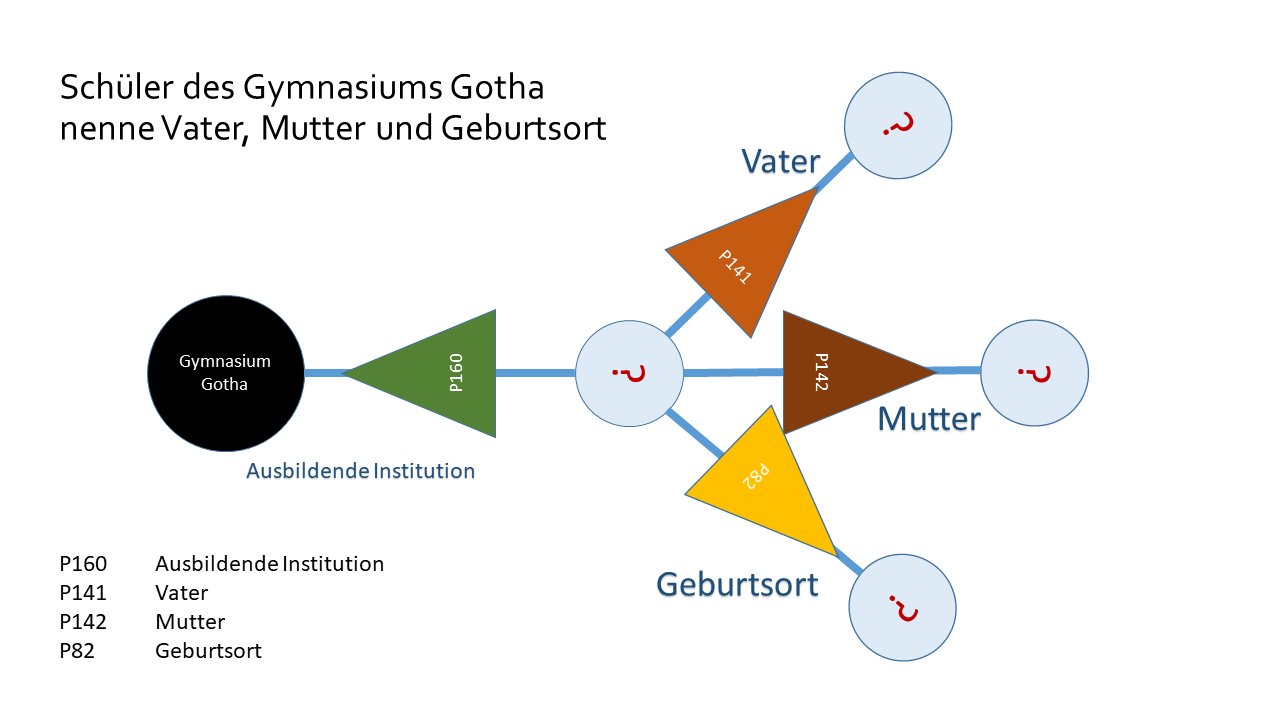
Wikibase steht im Ruf, ganz beliebige Information aufnehmen zu können. Auf einer einzigen Instanz kann man Information ganz verschiedener Fächer zusammenlaufen lassen und sie nahtlos über alle Fachgrenzen hinweg durchdringen.
Das Geheimnis liegt in der Flexibilität Tripel-basierter Daten. Wir können beliebige Objekte aufmachen und Aussagen zu ihnen beliebig an dokumentierte Datenstrukturen anpassen. Die Eingabe ist einfach. Komplizierter und offener ist, wie man die Daten danach in ihrer ganzen Vernetzung intelligent auswertet.
Ein Blick in die Datenmodellierung, die FactGrid Sample Searches und den Query-Service.
28.4.2022: Daten in 400 Sprachen verfügbar machen

Jahrzehntelang kämpfte man in der Bibliothekslandschaft um globale Datenmodelle und verbindliche Datenbank-Feldbelegungen in der Hoffnung, auf sichere Standards. All das hat das Wikidata-Projekt in seiner mutmaßlichen Notwendigkeit relativiert mit dem Angebot einer einzigen Ressource, die jede in ihr gespeicherte Aussage jederzeit in über 400 Sprachen verfügbar macht.
Wie das geht, ist im wörtlichen Sinne trivial: Alle Aussagen werden zerlegt in Datentripel von jeweils zwei Objekten und einer Beziehung zwischen ihnen, deren Teile man nun einzeln in beliebigen Sprachen mit beliebig vielen Labeln belegen kann. Tatsächlich können auf einer solchen Plattform Nutzer, ohne noch über eine gemeinsame Sprache zu verfügen, die Daten aller anderen in der eigenen Sprache lesen – eine gewaltige Chance für Projekte, die in Teams über Sprachgrenzen hinweg zusammenarbeiten sollen.
Ein Blick auf das Wikidata-Projekt, seine Software und Mehrsprachigkeit im FactGrid.
5.5.2022: Selbstorganisation über Projektgrenzen hinweg
Das FactGrid arbeitet ohne zentrale Redaktion, die Daten erst einmal ansehen und auf ihre Qualität hin überprüfen würde. Auch gibt es keine „Relevanzkriterien“ – keine Kriterien, die festlegen, was für Daten in die Datenbank dürfen. Wir arbeiten mit einer verwirrenden Offenheit, die dafür ganz eigene Grenzen hat: Forschungsprojekte (auch private) stehen für ihre Arbeit extrem transparent ein. Wir sind hier an einigen interessanten Stellen anders organisiert als Wikidata.
Wie das in der Praxis geht, welche Konflikte man einkalkulieren und welche Konfliktzonen man eher nicht fürchten sollte – Erkundungen der Plattform-Architektur und der speziellen Freiräume, die wir in ihr Projekten gewähren.
12.5.2022, unusual time 9:00: 350.000 Keilschriftartefakte — Daten als universelle Sprache — session in English with Adam Anderson, Berkeley

Das FactGrid Cuneiform Project dürfte im Moment eines der spannendsten auf der ganzen Plattform sein: Geplant ist hier, für alle gut 350.000 überlieferten Keilschrift-Artefakte Datenbankobjekte anzulegen und diese zu vernetzen. Wo wurden diese Objekte gefunden? Was für Ereignisse, welche Personen, welche Orte sind auf ihnen vermerkt? Spannend hieran ist nicht zuletzt das Ziel, eine ganze globale Fachcommunity mit ihrer kompletten Materialbasis auf die Plattform zu holen – die anders als andere Plattformen Keilschriftzeichen bequem darstellt und Informationen zu ihnen beliebig verfügbar macht.
Ist es klug, Informationen zu Sumererischen Sigeln neben Theatertruppen des 20. Jahrhundert handhaben? Vielleicht – denn wir können damit Forschungsgrenzen neuartig aufheben.
19.5.2022: Georeferenzierte Objekte — Session with Bruno Belhoste in English

Eine Aufgabe, vor der DH-Projekte immer wieder stehen, ist es, Information auf Landkarten zu visualisieren. Räumliche Beziehungsnetze werden sichtbar, Nähe wird greifbar wie der Horizont, den Verfasser mit Korrespondenzen hatten. Soziale Phänomene, etwa die Zusammensetzung der Bevölkerung in verschiedenen Stadtvierteln, lassen sich erfassen. FactGrid-Information ist jederzeit georeferenzierbar. Wir bieten Georeferenzierungen in einem ersten Projekt – Paris to Download – zur beliebigen Nutzung auf der Plattform oder in anderen Software-Umgebungen an. Einige Blicke auf die Projekte und die Software, die hier nach neuen Modulen ruft.
26.5.2022: Genealogie im FactGrid – mehr als nur Väter und Mütter
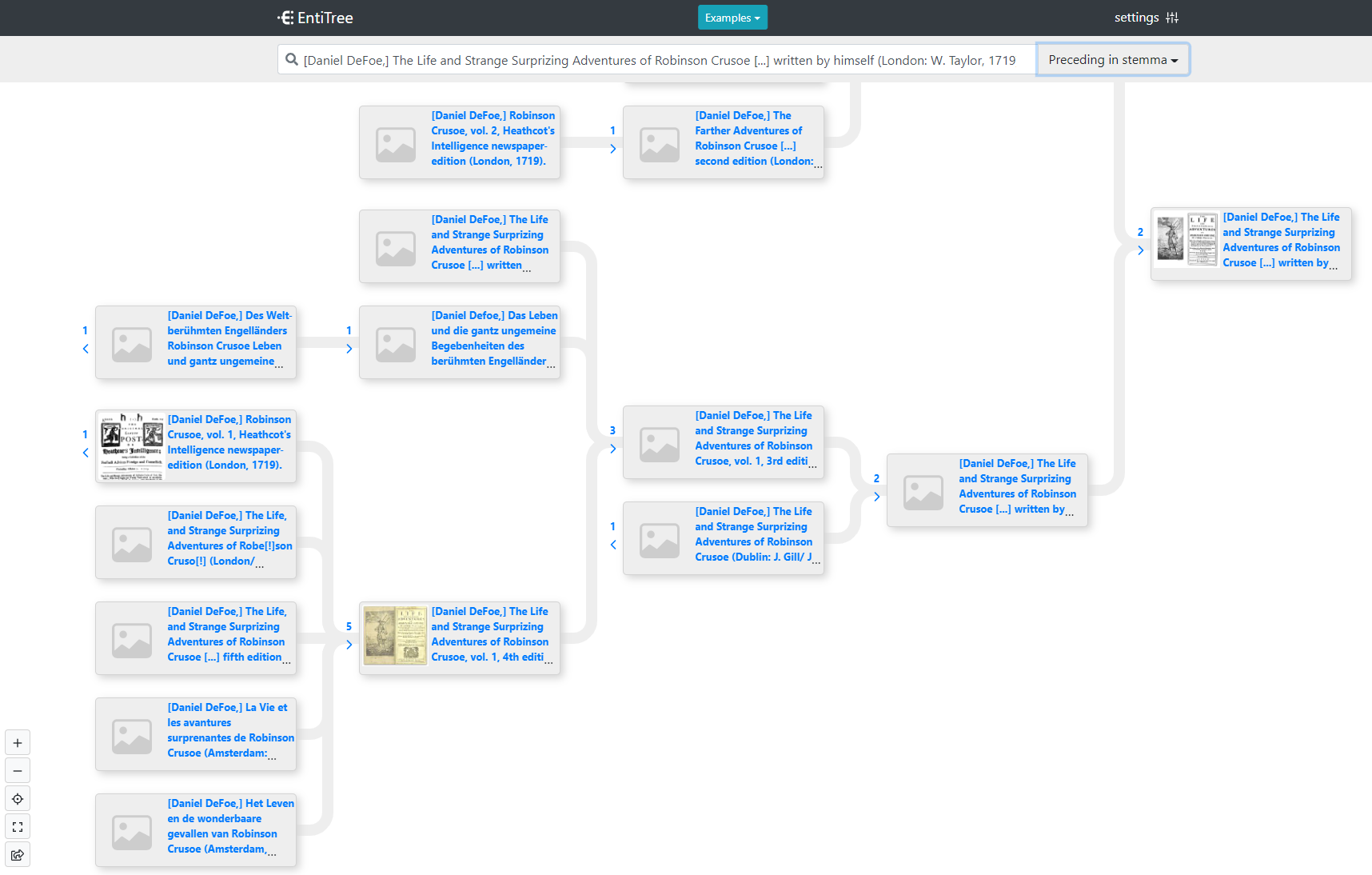
FactGrid-Information lässt sich komplex in externe Projekte hineinspielen. Zwei FactGrid Browsing-Tools stehen zu Verfügung. Es lassen sich jedoch auch ganz andere Werkzeuge denken.
Als überraschend vielseitig verwendbar erweist sich die von Orlando Groppo und Martin Schibel entwickelte EntiTree-App, die Genealogien auf bequeme Art und Weise mehrsprachig sichtbar macht. Spannende ist dass sich mit der EntiTree App auch noch ganz andere genealogische Beziehungen darstellen lassen.
2.6.2022: Können Studenten das FactGrid nutzen?
Ein klares Ja – das FactGrid steht allen offen, die historische Daten in einer kollektiv offenen Datenbank handhaben wollen. Man kann beliebige Daten aus dem FactGrid beziehen und beliebige eigene Daten in ihm ablegen und sie damit frisch halten.
Verschätzen sollte man sich allerdings nicht: Datengetriebe Forschung ist eher mit langem Atem betriebene Forschung – es sei denn, man wertet bestehende Daten aus (die man dazu aus anderen Quellen bei uns einspielen und nach eigenen Interessen bearbeiten kann).
Was muss man bedenken? Was muss man können? Was für Schwierigkeiten stellen sich, sobald man in das Feld der Digital Humanities einsteigt?
9.6.2022: Die Zukunft im NFDI4Memory Gefüge – oder: Dateninseln zu neuem Leben erwecken
Das FactGrid ist seit 2021 gesetzt, um im geplanten NFDI4Memory-Konsortium der deutschen Geschichtswissenschaften als Wikibase-Instanz zur Verfügung zu stehen. Forschungsdatenmanagement ist hier das Thema. Was geschieht mit Forschungsdaten, die am Ende irgendwie übrigbleiben – gesammelt, um den Arbeitsprozess zu begleiten, doch danach irgendwie nutzlos, indes voller Korrekturen und Einblicke, die zukünftiger Forschung nutzen sollten? Was geschieht mit Daten, die bislang auf einer eigenen Plattform laufen, nachdem deren Förderung endet? Wie kann man Daten langfristig sichern?
Das FactGrid will hier die Ressource sein, die Information kollektiv nutzbar macht und langfristig in Zirkulation und Korrektur hält. Praktische Tipps, wie das gehen könnte.